Efficient Streaming Language Models with Attention Sink - Xiao et al.
Insights from "Efficient streaming language models with Attention Sink (Xiao et al.)"

Motivation
LLMs tend to be used a lot in multi turn dialogues with long context.
Inference latency and memory scale with context because KV cache grows; additionally, some models exhibit degraded perplexity under naive windowing even when long-range dependencies are irrelevant..
Key Takeaways
Introduced “attention sink” phenomenon: LLMs assign disproportionately high attention to initial tokens
Attention sinks cause streaming failure even when recent context is sufficient and long term memory is not required.
Introduced StreamingLLM framerwork and pretraining with Sink tokens: enabled efficient text generation from recent tokens without frequent cache refreshes enabling long streaming contexts.
Core Constraints final solution resolves:
Efficiency and Memory Constraints:
Storing KV cache for all previous tokens leads to excessive memory consumption and increased decoding latency as length grows
Limited Length Extrapolation:
Generalization fails even after using RoPE (Rotary Position Embeddings) when run for longer context than it’s trained on.
Note: It’s important to focus that the final solution focuses on length extrapolation and memory and computation improvement for cases which would have performed well on small context but fails on long context ie they only depend on the local / nearby information.
The paper is not building solutions for long term memory or increasing the context window of LLM.
Core Challenge:
How can we support unbounded streaming inference with limited memory, stable performance and improved efficiency?
Possible solutions and challenges associated with them:
Dense Attention
Keeps all previous tokens KV cached uptil T tokens
Poor efficiency
Fails when cache limit hits
Window Attention
Keeps only most recent L tokens KV cached
Improves efficiency
Fails when initial tokens starts getting evicted
Sliding Window attention with recomputation
Recomputes hidden states for last L tokens at every step
Performs well on long text
Loses efficiency has to recompute KV states for every token
Key Insight: Attention Sink
Eviction from KV cache of initial token collapses model’s performance for sliding window attention.
Phenomenon:
Initial tokens receive disproportionate fraction of attention scores.
Initial tokens doesn’t have to be semantically important.
More pronounced in deeper layers.
Why do attention Sink form?
SoftMax function requires model to sum up to 1.
This normalization forces model to allocate attention to somewhere.
Why initial tokens become sink?
Autoregressive nature of pretraining makes initial token visible to all subsequent tokens.
They act as stable fallback for dumping attention weights.
Why evicting sink tokens cause instability?
Based on the below formula:
\(\mathrm{softmax}(z_i) \;=\; \frac{e^{z_i}}{\sum_{j=1}^{K} e^{z_j}} \)When kv cache evicts the initial token, as we noted, the initial tokens are attention sink and hence carry most weights.
This causes significant impact on denominator
Causing change in attention distribution ultimately leading to sharp perplexity spike.
Solutions
Based on above insights it would be great if readers pause for 5 minutes and think about simple solutions. Interestingly they work!!
Streaming LLM Framework
1. Rolling KV Cache with Attention Sinks
Keep a rolling window of recent tokens, the model keeps both the first few “sink” tokens and rolling window of recent tokens.
Reassign the position based on `within the cache` rather than those in original text making position sequential.
2. Pretraining with Softmax off by one in attention
Formula :
\(\mathrm{softmax}(z_i) \;=\; \frac{e^{z_i}}{ 1 + \sum_{j=1}^{K} e^{z_j}} \)Doesn’t require attention scores to sum up to one.
Essentially prepending model with all zero key and value
Works but require other initial tokens too in cache.
3. Pre Training with Sink tokens [trainable]
Pre Train a model with a trainable Sink Token
Only requires sink token instead of few initial tokens.
Experiments to show solution efficacy:
a. Perplexity remain stable even till 4 million context range across different LLMs

b. Significant reduction in decoding latency
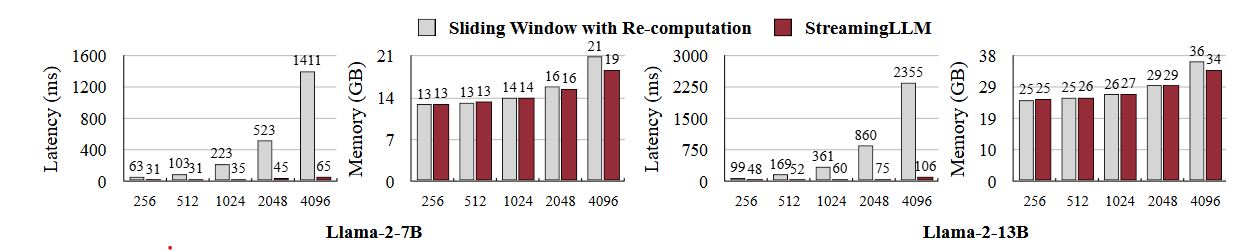
c. Less attention to other initial tokens when pre trained with sink tokens and clear attention directed towards sink token across all layers.

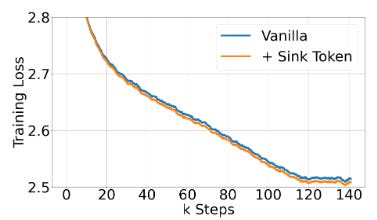
d. No change in convergence times and training loss after adding sink tokens
Remarks
Positives:
a. Thorough coverage of the phenomenon, with breadth of examples to disprove different hypothesis or alternative explanation.
b. Building a simple and extremely effective solution after getting insights from underlying problem.
c. Well explained and clearly written
Negatives:
a. There was no confidence interval across results and was difficult to understand whether one method is statistically superior method.
b. Better baselines: I found the baselines to be very simple.
Instead of having kv cache with recomputation do it after some s strides. One can balance number of recomputation [computational inefficiency] with perplexity score [performance improvement]
It’s worth to add comparisons with random baselines. One such example would be instead of initial 4 tokens. Take random 4 tokens to see compare improvement.
c. Possible explanation why window attention doesn’t fail for pythia and falcon but failed for llama and MPT in Figure 3 of paper.
Future Work
Another solution could be to try out diffusing the emphasis on initial token
Recently neurips paper on Gated Attention shows it can be done through gated attention.
Maybe adding a penalizing factor while training after certain length attention can’t be consistently high on one particular token across samples based on position.
Dispersed trainable sink tokens instead of at the start either randomly or at some strides.
References:
Xiao et al., Efficient Streaming Language Models with Attention Sinks